Decreasing RAM Usage by 40% Using jemalloc with Python & Celery

At Zapier, we're running hundreds of instances of Python and Celery, a distributed queue that helps us perform thousands of tasks per second. With that kind of load, the RAM usage has become a point of contention for us.
To process all the activity within our service, we run about 150 Celery workers with the settings -w 92 on our m3.2xlarge – which means each worker got approximately ~320 MB of RAM. This should have been plenty, yet it wasn't uncommon to have 8-12 GB of swap usage on a worker after a couple hours running normally. Not only was this taxing our RAM, it was also preventing us from upgrading to newer versions of Amazon hardware which didn't have the faster instance store enabled over EBS.
Further, we noticed that most of this memory usage smelled a bit like fragmentation –tons of memory pages were being moved to swap but it didn't seem to hurt performance at all. Clearly Celery or our Python code wasn't touching these fragmented pages of memory very often.
Familiar with the memory allocator jemalloc from Redis and how well it handles fragmentation, we decided to experiment using jemalloc with Python.
The Setup
First we need to install jemalloc. We got our bits from the jemalloc GitHub repo and followed the classic instructions:
# installing jemalloc wget https://github.com/jemalloc/jemalloc/releases/download/5.1.0/jemalloc-5.1.0.tar.bz2 tar xvjf jemalloc-5.1.0.tar.bz2 cd jemalloc-5.1.0 ./configure make sudo make install
Then we set up our Python app:
# running your app LD_PRELOAD=/usr/local/lib/libjemalloc.so python your_app.py
We chose a few servers for a canary, deployed the change, and watched the graphs.
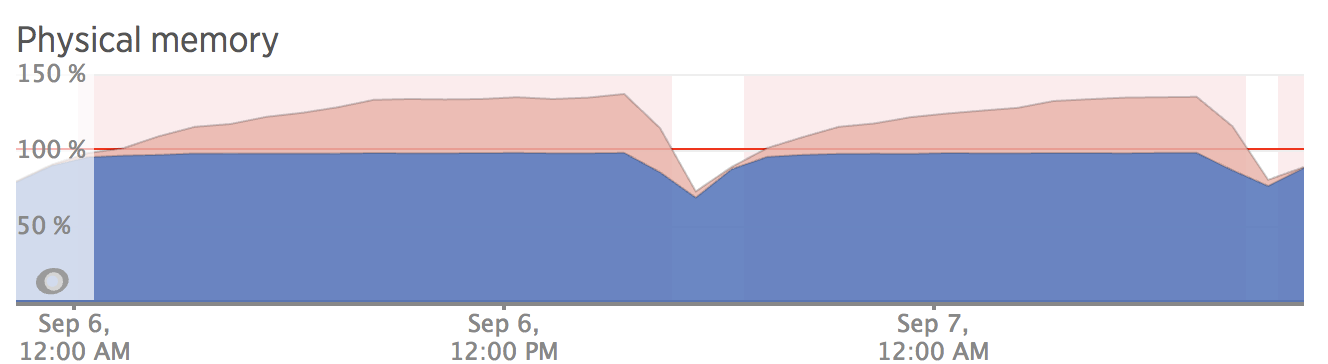
Using the vanilla Python malloc
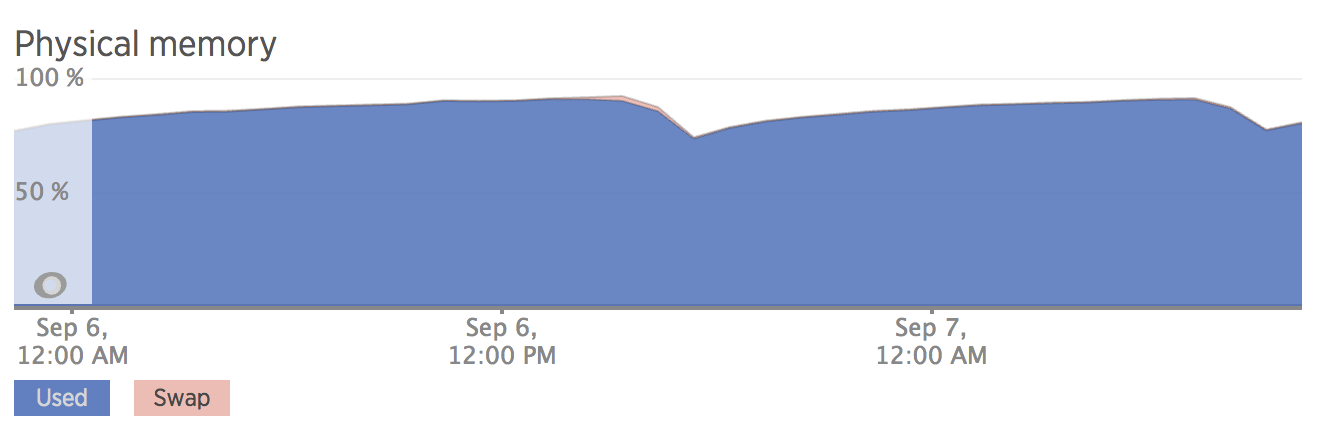
Using jemalloc 3.5.1
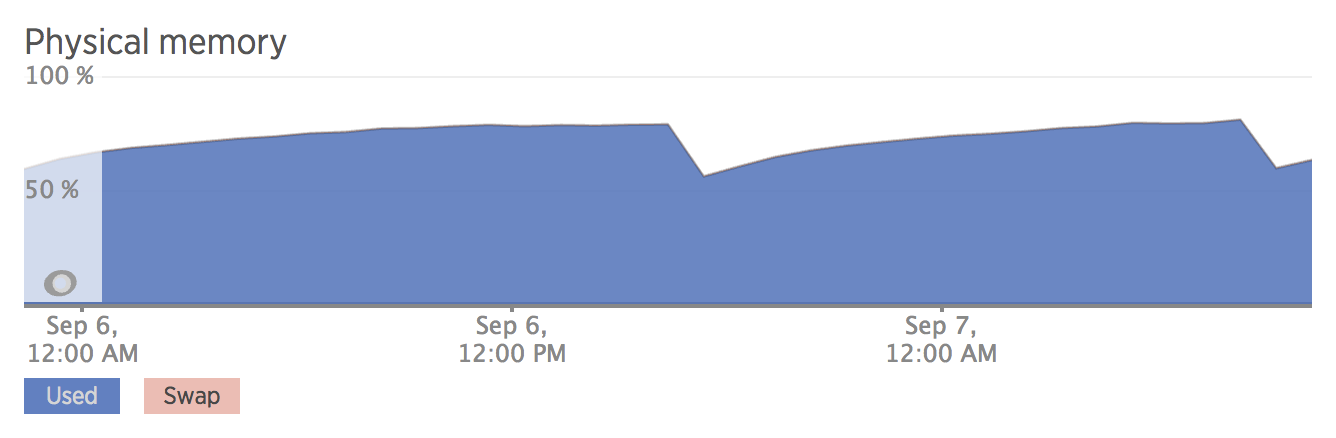
Using jemalloc 5.0.1
Final numbers
As the RAM usage grew in the vanilla, we saw a 30% decrease in RAM usage with 3.5.1 and a 40% decrease in RAM usage with 5.0.1! With vanilla malloc, we now have an average peak of 38.8gb vs 26.6gb for 3.5.1 and 22.7gb for 5.0.1.
The dips in the graphs were from routine deployments or restarts.
Why was this so effective?
We're not 100% sure, but the current working theory on memory fragmentation seems plausible. jemalloc is known to reclaim memory effectively (which is why Redis uses it to great effect).
Do you have more context on why this may be the case? Please leave a comment and let us know, we'd love to learn more!
We're hiring remote engineers from around the world! Check out our job posts here!
About the Author
Bryan Helmig is a co-founder and CTO at Zapier, jazz/blues musician and fine beer and whiskey lover.
Comments powered by Disqus