- Guides
- An introduction to APIs
- Protocols
Chapter 2: API protocols
By Bryan Cooksey • Updated January 19, 2024
In Chapter 1, we got our bearings by forming a picture of the two sides involved in an API: the server and the client. With a solid grasp on the who, we are ready to look deeper into how these two communicate. For context, we first look at the human model of communication and compare it to computers. After that, we move on to the specifics of a common protocol used in APIs.
API protocol rules
People create social etiquette to guide their interactions. One example is how we talk to each other on the phone. Imagine yourself chatting with a friend. While they are speaking, you know to be silent. You know to allow them brief pauses. If they ask a question and then remain quiet, you know they are expecting a response and it is now your turn to talk.
Computers have a similar etiquette, though it goes by the term "protocol." A computer protocol is an accepted set of rules that govern how two computers can speak to each other. Compared to our standards, however, a computer protocol is extremely rigid. Think for a moment of the two sentences "My favorite color is blue" and "Blue is my favorite color." People are able to break down each sentence and see that they mean the same thing, despite the words being in different orders. Unfortunately, computers are not that smart.
For two computers to communicate effectively, the server has to know exactly how the client will arrange its messages. You can think of it like a person asking for a mailing address. When you ask for the location of a place, you assume the first thing you are told is the street address, followed by the city, the state, and lastly, the ZIP Code. You also have certain expectations about each piece of the address, like the fact that ZIP Code should only consist of numbers. A similar level of specificity is required for a computer protocol to work.
HTTP: The protocol of the web
There is a protocol for just about everything, each one tailored to different jobs. You may have already heard of some: Bluetooth for connecting devices, and POP or IMAP for fetching emails.
On the web, the main protocol is the Hypertext Transfer Protocol, better known by its acronym, HTTP. When you type an address like http://example.com into a web browser, the "http" tells the browser to use the rules of HTTP when talking with the server.
With the ubiquity of HTTP on the web, many companies choose to adopt it as the protocol underlying their APIs. One benefit of using a familiar protocol is that it lowers the learning curve for developers, which encourages usage of the API. Another benefit is that HTTP has several features useful in building a good API, as we'll see later. Right now, let's brave the water and take a look at how HTTP works!
HTTP requests
Communication in HTTP centers around a concept called the Request-Response Cycle. The client sends the server a request to do something. The server, in turn, sends the client a response saying whether or not the server could do what the client asked.

To make a valid request, the client needs to include four things:
- URL (Uniform Resource Locator)
- Method
- List of headers
- Body
That may sound like a lot of details just to pass along a message, but remember, computers have to be very specific to communicate with one another.
The HTTP specification actually requires a request to have a URI (Universal Resource Identifier), of which URLs are a subset, along with URNs (Uniform Resource Names). We chose URL because it is the acronym readers already know. The subtle differences between these three are beyond the scope of the course.
URL
URLs are familiar to us through our daily use of the web, but have you ever taken a moment to consider their structure? In HTTP, a URL is a unique address for a thing (a noun). Which things get addresses is entirely up to the business running the server. They can make URLs for webpages, images, or even videos of cute animals.
APIs extend this idea a bit further to include nouns like customers, products, and tweets. In doing so, URLs become an easy way for the client to tell the server which thing it wants to interact with. Of course, APIs also do not call them "things", but give them the technical name "resources."
Method
The request method tells the server what kind of action the client wants the server to take. In fact, the method is commonly referred to as the request "verb."
Some of the most common API methods are:
- GET: Asks the server to retrieve a resource
- POST: Asks the server to create a new resource
- PUT: Asks the server to edit/update an existing resource
- PATCH: Asks the server to partially edit/update an existing resource
- DELETE: Asks the server to delete a resource
Here's an example to help illustrate these methods. Let's say there is a pizza parlor with an API you can use to place orders. You place an order by making a POST request to the restaurant's server with your order details, asking them to create your pizza. As soon as you send the request, however, you realize you picked the wrong style crust, so you make a PATCH request to change only the crust style (as opposed to a PUT request, which you would use to change the entire resource/order).
While waiting on your order, you make a bunch of GET requests to check the status. After an hour of waiting, you decide you've had enough and make a DELETE request to cancel your order.
Headers
Headers provide meta-information about a request. They are a simple list of items like the time the client sent the request and the size of the request body.
Every time you visit a website on your smartphone that's been specially rendered for mobile devices, this formatting is made possible by an HTTP header called "User-Agent." The client uses this header to tell the server what type of device you are using, and websites smart enough to detect it can send you the best format for your device.
There are quite a few HTTP headers that clients and servers deal with, so we will wait to talk about other ones until they are relevant in later chapters.
Body
The request body contains the data the client wants to send the server. Continuing our pizza ordering example above, the body is where the order details go.
A unique trait about the body is that the client has complete control over this part of the request. Unlike the method, URL, or headers, where the HTTP protocol requires a rigid structure, the body allows the client to send anything it needs.
These four pieces—URL, method, headers, and body—make up a complete HTTP request.

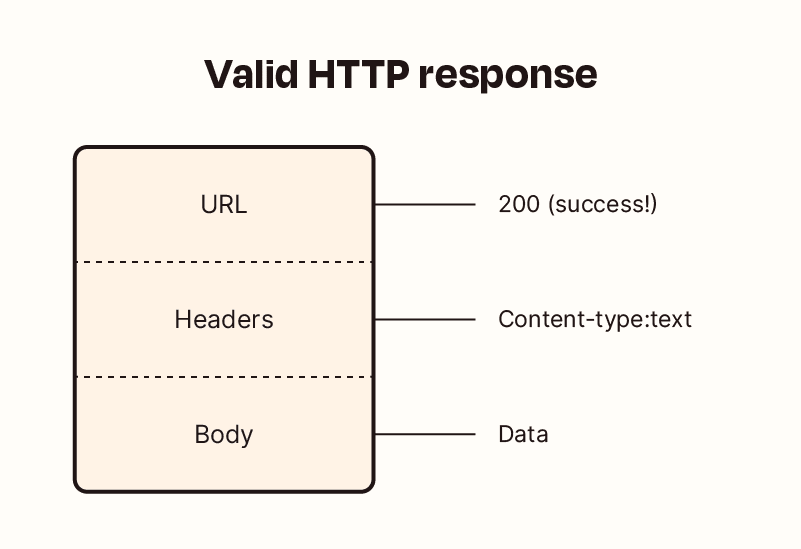
HTTP responses
After the server receives a request from the client, it attempts to fulfill the request and send the client back a response. HTTP responses have a very similar structure to requests. The main difference is that instead of a method and a URL, the response includes a status code. Beyond that, the response headers and body follow the same format as requests.
Status codes
Status codes are three-digit numbers that each have a unique meaning. When used correctly in an API, this little number can communicate a lot of info to the client. For example, you may have seen this page during your internet wanderings:

The status code behind this response is 404, which means "Not Found." Whenever the client makes a request for a resource that does not exist, the server responds with a 404 status code to let the client know: "that resource doesn't exist, so please don't ask for it again!"
There is a slew of other statuses in the HTTP protocol, including 200 ("success! that request was good") to 503 ("our website/API is currently down.") We'll learn a few more of them as they come up in later chapters.
Completing the cycle
After a response is delivered to the client, the Request-Response Cycle is completed and that round of communication is over. It is now up to the client to initiate any further interactions. The server will not send the client any more data until it receives a new request.
How APIs build on HTTP
By now, you can see that HTTP supports a wide range of permutations to help the client and server talk. So, how does this help us with APIs? The flexibility of HTTP means that APIs built on it can provide clients with a lot of business potential. We saw that potential in the pizza ordering example above. A simple tweak to the request method was the difference between telling the server to create a new order or cancel an existing one. It was easy to turn the desired business outcome into an instruction the server could understand. Very powerful!
This versatility in the HTTP protocol extends to other parts of a request, too. Some APIs require a particular header, while others require specific information inside the request body. Being able to use APIs hinges on knowing how to make the correct HTTP request to get the result you want.
Chapter 2 recap
The goal of this chapter was to give you a basic understanding of HTTP. The key concept was the Request-Response Cycle, which we broke down into the following parts:
- Request: Consists of a URL (http://…), a method (GET, POST, PUT, PATCH, DELETE), a list of headers (User-Agent…), and a body (data)
- Response: Consists of a status code (200, 404…), a list of headers, and a body
Throughout the rest of the course, we will revisit these fundamentals as we discover how APIs rely on them to deliver power and flexibility.
Next
In the next chapter, we explore what kind of data APIs pass between the client and the server.
Published April 2014; last updated January 19, 2024.
Previous chapter:
Next chapter: